Entity Node
The Entity node connects to your data sources and retrieves data for processing. It's the starting point for most workflows, providing access to database tables, API endpoints, file data, and more.
How It Works
The Entity node:
- Connects to a configured data source (connection)
- Reads data from a specific entity (table, endpoint, file)
- Optionally filters or limits the data at the source
- Provides the data as rows for downstream processing
Adding an Entity
- Drag Entity from the Inputs section of the Element Panel
- Click the Entity node to configure it
- Select a connection and entity
- Configure any filters or options
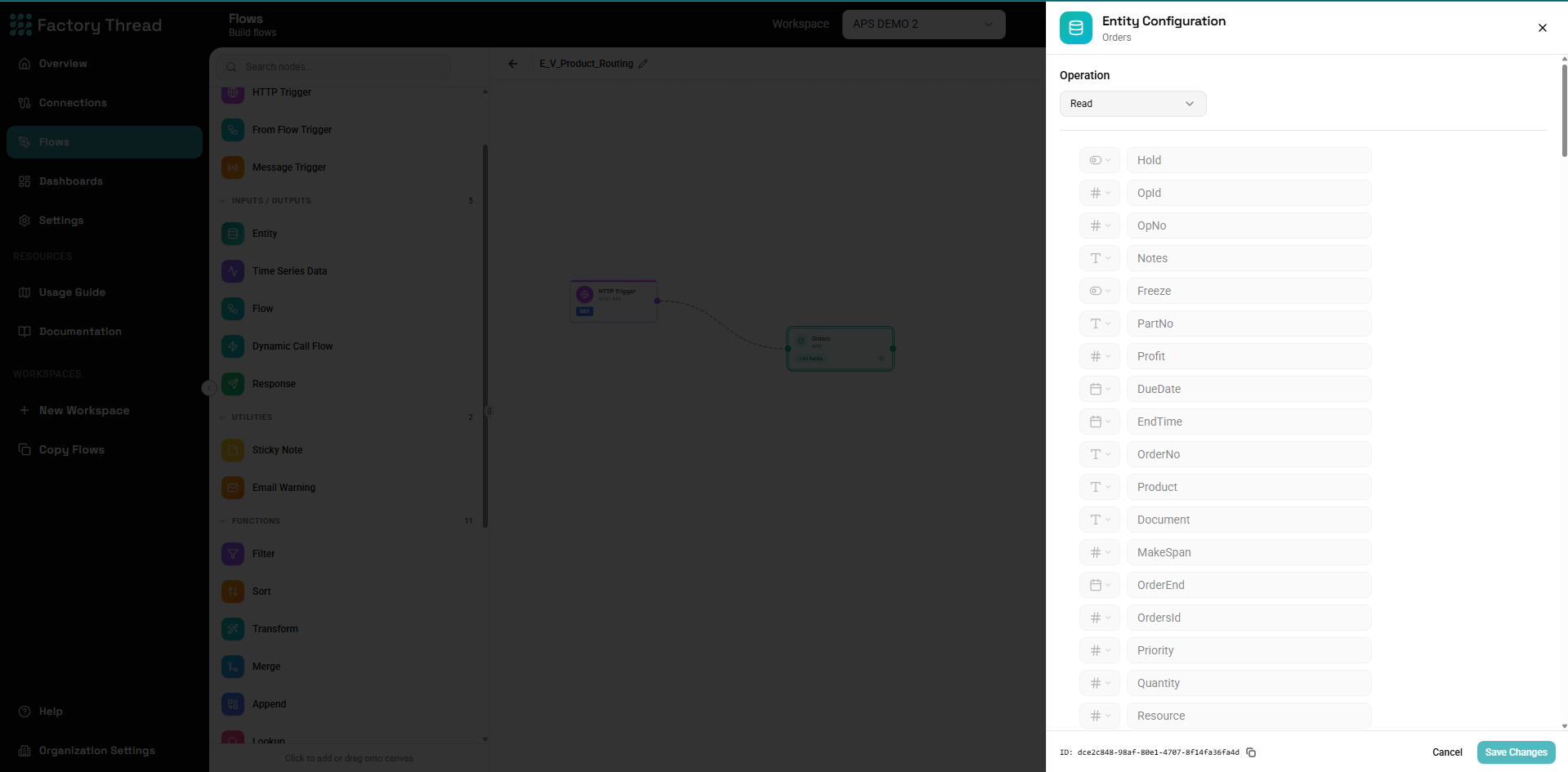
Configuration Panel
Connection Selection
Choose Connection: Select from your configured connections. Only connections with discovered entities appear.
Connection Types:
- MES / MOM - Opcenter, Plex, Acumatica, i3X, OPC UA
- Databases - SQL Server, PostgreSQL, Redshift, DB2, InfluxDB
- Files - Excel, CSV, TXT (Upload, Local Files, SharePoint)
- APIs - REST, OData, SOAP
If needed connections aren't available, configure them in the Connections page first.
Entity Selection
Choose Entity: After selecting a connection, choose the specific entity:
For Databases:
- Tables
- Views
- Stored procedures (with parameters)
For Files:
- Sheets (Excel)
- File paths (CSV)
For APIs:
- Endpoints
- Resources
Entity Schema
Once selected, the schema panel shows:
- Field Name - Column/property name
- Data Type - Text, Number, Date, Boolean, etc.
- Nullable - Whether field can be null
- Key - Primary key indicator
Use this to understand your data structure.
Source Filtering
Apply filters at the source level for efficiency:
Why Filter at Source?
Filtering at the entity reduces:
- Data transferred over the network
- Memory usage in processing
- Execution time
Push-down filtering happens at the database/API level.
Adding Source Filters
- Click Add Filter
- Select field, operator, and value
- Combine multiple filters with AND/OR
Example:
Status = "Active"
AND
CreatedDate > 2024-01-01
Dynamic Filters with Parameters
Use trigger parameters for dynamic filtering:
HTTP trigger parameter:
CustomerID = {customerId}
Schedule trigger parameter:
ProcessDate >= {lastRunDate}
Row Limit
Limit the number of rows retrieved:
Fixed limit:
- Limit: 1000 rows
- Useful for testing or previewing
Parameter-based limit:
- Limit:
{maxRows} - Controlled by trigger parameters
No limit:
- All rows returned (default)
- Use with caution on large tables
Column Selection
Select specific columns to retrieve:
All columns (default): All fields from the entity are included.
Selected columns:
- Click Select Columns
- Check the columns you need
- Unchecked columns are not retrieved
Benefits of selecting columns:
- Faster data retrieval
- Less memory usage
- Cleaner downstream processing
Ordering
Sort data at the source:
Add Sort:
- Select field
- Choose Ascending or Descending
- Add additional sort levels if needed
Benefits:
- Database indexes can optimize sorted retrieval
- Data arrives in expected order
Entity Types
Database Tables
Direct table access:
- Full table data
- All CRUD operations supported
- Filters translate to WHERE clauses
Configuration:
Connection: Production Database
Entity: Orders
Columns: OrderID, CustomerID, OrderDate, Total
Filter: Status = 'Completed'
Order By: OrderDate DESC
Limit: 10000
Database Views
Pre-defined queries:
- Business logic already applied
- May include joins and calculations
- Read-only typically
Configuration:
Connection: Reporting Database
Entity: vw_SalesAnalysis
Stored Procedures
Parameterized queries:
- Complex business logic
- May accept parameters
- Results as entity output
Configuration:
Connection: Production Database
Entity: sp_GetOrdersByDateRange
Parameters:
- StartDate: {startDate}
- EndDate: {endDate}
Excel Sheets
Spreadsheet data:
- Each sheet is an entity
- Headers become field names
- Data types auto-detected
Configuration:
Connection: Sales Reports (Excel)
Entity: January2024
CSV Files
Delimited text:
- Single entity per file
- Headers required (or specified)
- Configurable delimiters
Configuration:
Connection: Data Files (CSV)
Entity: customers.csv
API Endpoints
REST/OData data:
- Endpoints as entities
- Parameters passed to API
- JSON/XML responses parsed
Configuration:
Connection: CRM API
Entity: /api/v2/customers
Parameters:
- status: active
Multiple Entities
Workflows often use multiple Entity nodes:
Parallel Data Sources
Load from multiple sources simultaneously:
[Orders Entity] ─────────────────┐
├─ [Merge] → [Process]
[Customers Entity] ──────────────┘
Both entities execute in parallel.
Sequential Dependencies
When one entity depends on another's results:
[Config Entity] → [Formula: extract IDs] → [Filter uses IDs] → [Main Entity]
Use parameters to pass values between entities.
Data Type Handling
Automatic Type Detection
Entity nodes detect types from the source schema:
- Databases: Types from column definitions
- APIs: Types from response schema
- Files: Inferred from data samples
Type Display
Schema panel shows detected types:
- String/Text - Character data
- Number/Integer/Decimal - Numeric data
- DateTime/Date - Date and time values
- Boolean - True/false values
- Object/Array - Complex nested data
Type Conversion
If types need adjustment:
- Use Formula after Entity
- Apply TO_NUMBER, TO_STRING, TO_DATE functions
- Handle conversion errors appropriately
Performance Optimization
Filter at Source
Best practice: Apply filters at the entity level
Less efficient:
[Entity: All Orders] → [Filter: Status = Active]
More efficient:
[Entity: Orders WHERE Status = Active]
Database-level filtering is orders of magnitude faster.
Select Needed Columns
Best practice: Select only required columns
Less efficient:
[Entity: All 50 columns] → [Map: select 5]
More efficient:
[Entity: 5 columns selected]
Use Indexes
When filtering or sorting:
- Filter on indexed columns when possible
- Order by indexed columns
- Coordinate with database administrators
Limit During Development
While building workflows:
- Set reasonable limits (100-1000 rows)
- Validate logic with sample data
- Remove limits for production
Batch Processing
For very large datasets:
- Use date-based filtering for batches
- Process incrementally
- Consider scheduled batch jobs
Error Handling
Connection Errors
Symptoms: Entity fails to load data
Common causes:
- Connection credentials invalid
- Network connectivity issues
- Database/API unavailable
- Firewall blocking access
Solutions:
- Test connection in Connections page
- Verify credentials
- Check network connectivity
- Review firewall rules
Schema Changes
Symptoms: Expected fields missing
Common causes:
- Table/entity structure changed
- Column renamed or removed
- New columns added
Solutions:
- Re-discover entities in Connections
- Update entity configuration
- Adjust downstream processing
Data Type Errors
Symptoms: Unexpected values or conversion failures
Common causes:
- Source data quality issues
- Mixed types in columns
- Null values
Solutions:
- Add data validation transforms
- Handle nulls explicitly
- Check source data quality
Timeout Errors
Symptoms: Entity retrieval times out
Common causes:
- Too much data
- Slow database query
- Network latency
Solutions:
- Add filters to reduce data
- Add indexes to database
- Increase timeout settings
- Break into smaller batches
Common Patterns
Master-Detail Pattern
Load master records with details:
[Master Entity: Customers] ─┐
├─ [Merge on CustomerID]
[Detail Entity: Orders] ────┘
Lookup Reference Data
Combine transactional with reference data:
[Transactions Entity] → [Lookup: Status Codes] → [Lookup: Customers]
Incremental Load
Load only new/changed data:
Entity Configuration:
Filter: ModifiedDate > {lastRunDate}
Schedule trigger provides lastRunDate parameter.
Parameterized Retrieval
Entity filters from trigger parameters:
HTTP trigger flow:
Entity Filter: CustomerID = {customerId}
User passes customerId in API request.
Entity Node Options
Preview
Click Preview to see sample data:
- Shows first N rows
- Validates configuration
- Displays actual schema
Refresh Schema
If source schema changed:
- Click Refresh Schema
- Re-discovers entity structure
- Updates field list
Test Connection
Verify connection is working:
- Click Test
- Confirms connectivity
- Reports any errors
Examples
Sales Data Extraction
Goal: Extract completed orders from last 30 days
Configuration:
Connection: ERP Database
Entity: SalesOrders
Columns: OrderID, CustomerID, OrderDate, Total, Status
Filter: Status = 'Completed' AND OrderDate >= DATEADD(day, -30, GETDATE())
Order By: OrderDate DESC
Customer Sync
Goal: Get active customers for sync
Configuration:
Connection: CRM System
Entity: Customers
Filter: IsActive = true
Columns: CustomerID, Name, Email, Phone, LastModified
Daily Inventory Snapshot
Goal: Complete inventory status
Configuration:
Connection: Warehouse DB
Entity: InventoryLevels
Columns: SKU, Warehouse, Quantity, ReorderPoint, LastUpdated
Order By: Warehouse, SKU
API Data Retrieval
Goal: Get customer from external API
Configuration:
Connection: External CRM API
Entity: /customers
Parameters:
- id: {customerId}
- includeOrders: true
Writing data back
The Entity node doesn't only read — it can write back to a source system. In the panel, set Operation to Update (instead of Read). Map your incoming fields to the target's columns, then choose how the write behaves:
- Append new records — add the incoming rows
- Update current records — update existing rows (requires identifier columns)
- Clear all records — empty the target before writing
- Delete old records — remove rows no longer present in the incoming data
- Delete current records — remove the incoming rows from the target
Write-back to a database is supported for SQL Server, PostgreSQL, IBM DB2, and Opcenter APS, and to file connections (Upload, Local Files, SharePoint). InfluxDB and file targets are append-only — they accept new records only. OPC UA is read-only and cannot be set to Update.
Writing back is an irreversible operation. Preview your data and start with a small, filtered set before enabling Update against a production system.
Next Steps
- CallFlow Node - Invoke sub-flows
- Response Node - Return data from API flows
- Classify Node - Categorize records with AI
- Connections Overview - Configure connections
- Building Flows - Complete workflow guide